Some thoughts on building Realtime Compute at Tecton

I learned recently that Tecton was getting acquired by Databricks, and with that I also I started to think about the cool work that my team and I worked on that we never got to blog about. Seeing as how it's unlikely that we'll see a Tecton blog about those projects, I figure it's a good time to do it myself.
So, before I left, I was working on building realtime infrastructure at Tecton; specifically Server Groups and Stream Ingest API as part of the Realtime Compute team. I think both are super interesting problems and I thought our approach to them was pretty pragmatic and performant, and I specially wanted to shout out my whole team (Pooja, Sanika, Christopher, and many more) that help build the infrastructure I'm about to describe. But before that, I want to discuss what a feature store is, and why one would care about streaming at all.
What's a feature store
And where does streaming fit in?
There's plenty that has already been written about feature stores, and I don't want to rehash that. Fundamentally, a feature store makes feature data available to systems to support model training and model inference. Model training requires timestamped, historical data and support for training data generation which is point-in-time correct. Typically this data lives in some kind of offline store which supports large data volumes and higher latency/complicated queries. Model inference on the other hand, requires extremely low latency point-value lookups. Typically, this data is served via some API (HTTP/Json or gRPC), and the data is stored in some kind of online key-value store.
Where does streaming fit into all this? Two ways:
- Typically, we want to featurize data and store it in the offline store as soon as possible to enable frequent model training/retraining. Ingesting from realtime streams is a good way of doing that.
- Similarly, fresh feature data can also improve model performance for a bunch of use cases. So we want to new data to be reflected in the online store as quickly as possible.
Stream Ingest API
AKA PushAPI
Assuming I've convinced you of the importance of streams, lets talk about how this was commonly implemented.
A common pattern to use streams in feature stores is to have streaming applications consume real-time events from an organizations pre-existing messaging systems (like Kafka or Kinesis). These stream applications could be Spark Structured Streaming applications, or as I've alluded to in previous posts, Flink Applications.
Tecton was built on Spark for historical reasons, so all the streaming applications we'd stand up were Spark Structured Streaming apps that could consume from organizations' Kafka topics/Kinesis streams.
Another important point to note - Tecton was a single-tenant, cloud-native platform. This meant that we would run a control plane per customer tenant in one AWS sub-account (i.e. the Control Plane), and have customer-owned data live in a separate sub-account (i.e. the Data Plane), typically owned by customers. They'd have to grant cross account permissions to specific Tecton IAM users that would have access to write data to the Data Plane.
So, in this setting, what problems did we see with streams in practice?
- Access to an organization's Kafka cluster is tough to get. Kafka often acts as an organizations' backbone, so allowing vendors access needs a lot of vetting. It's also technically non-trivial, as AWS docs will attest to (though granted this has gotten easier over time).
- Streaming applications usually don't give users any SLO on when data is consumed and "available" at read time. In the best case, data should be available the trigger interval duration after ingestion (assuming a lot of good luck). In reality.. lots of stuff can can affect this.
- The stream can be very high volume, or the stream application may not be scaled enough, which can make the streaming app start to build up lag.
- The streaming app could crash (as things often do) and cause lag to build up.
- Any transformations/projections/enrichments in the streaming app could dominate processing time.
- Costs can be high. Imagine a low volume stream, for which we need to spin up a Spark Structure Streaming application. That's a minimum of 1 driver node and 1 worker node that's running 24x7, regardless of there's events to process or not. If running Spark jobs on EMR, checkpointing costs are also pretty high (Databricks uses DBFS which is much cheaper, but that's a big platform shift).
Enter Stream Ingest API. The idea here was pretty simple - move from a pull-based architecture, to a push-based architecture. This was something that I had worked on when we were building Feast as well, and the architectural advantages were substantial.
- By running the Stream Ingest API as a service in the Data Place, we could preserve data residency requirements. Also, we could pass along infrastructure costs to users, which aligned incentives.
- The Stream Ingest API was be a multi-tenant system for multiple features. the one at Tecton was built in Kotlin. It was pretty performant and could be cheaper than a streaming equivalent up (fewer nodes for equivalent records/sec).
- I personally also like the idea of exposing service APIs over libraries (i.e. a Spark Sink for Tecton). Service APIs can be updated in place, and we can implement new behaviour without needed users to upgrade their dependencies.
- For pull-based streaming apps, Tecton required a batch source for training dataset generation. But when using the API, could build logging to an offline store as a feature for users, obviating the need to bring their own offline data. The API could become a one-stop-shop for building a data platform for ML.
How did it work?
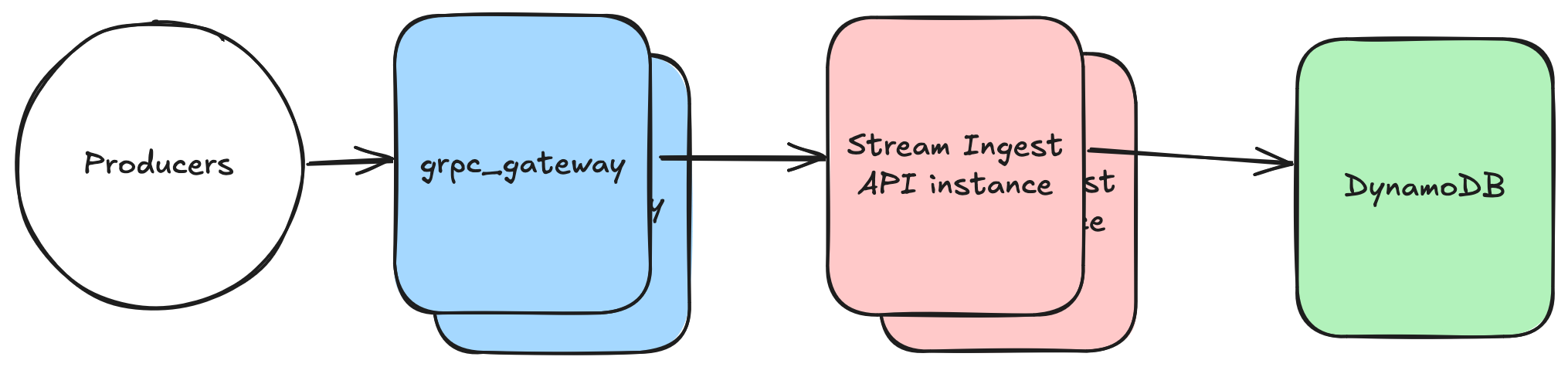
The Stream Ingest API was a grpc service, implemented in Kotlin, fronted by grpc-gateway to expose an HTTP/JSON API. Records could be batched in a single request, capped at 10records per request. Writes were made synchronously. In case of request failures, the whole request needed to be retried.
The service was designed to be stateless, which solved the problem of at-least-once/at-most-once delivery. Record delivery could be retried until producers got a success response.
Requests were validated strongly (required fields and types) against a schema that was pre-registered, and non-conformant records would return erroneous responses.
On launch, records once written could be edited, but this was highly discouraged 😅. The solution for this was to implement timestamping for each record when ingesting. This leads to a bi-temporal data model - user records have an "event" timestamp, provided by users, and an "ingestion" timestamp, applied by the system, providing immutability to records.
This obviously leads to the possibility of conflict between multiple concurrent write requests for the same event. Our system's behaviour was therefore "last-write-wins". In practice, this wasn't an issue since availability of the API was 99.99%.
Performance
A lot of the ingestion performance is highly dependent on the backing online store used. We used DynamoDB primarily.
Batch Size : 1
| 100 QPS | 500 QPS | 1000 QPS | |
|---|---|---|---|
| p50 | 57 | 55 | 55 |
| p90 | 71 | 69 | 67 |
| p95 | 86 | 81 | 76 |
| p99 | 165 | 127 | 108 |
Batch Size : 10
| 20 QPS | 100 QPS | 200 QPS | |
|---|---|---|---|
| p50 | 98 | 112 | 82 |
| p90 | 115 | 135 | 97 |
| p95 | 124 | 151 | 143 |
| p99 | 156 | 213 | 190 |
Integration with Streams

We made a sample Kafka consumer that could write to the Stream Ingest API, and all it needed for an endpoint and an API key for Tecton. That made adding Tecton to existing Data pipelines easy. Since integration involved writing
Phew. So that's basically what the Stream Ingest API did. I was pretty proud of it, we onboarding a few users to it before I left and it was scaling quite well.
One thing that is missing here however, is an understanding of how we would run UDFs on behalf of users when ingesting data via the Stream Ingest API, as well as tenancy for Ingestion Servers as well. That's a topic I'll cover in the next post, when I talk about Server Groups.