Realtime Compute V2


In my previous post, I talked about the problem of running compute on behalf of users, and some early iterations we built, and the problems we ran into.
Where we left off
We needed a way to run user code, on their behalf, to manipulate data that was being ingested into the platform, or read out of the platform.
We tried colocating this transformation process, to run into scalability and security issues. Moving the transformations to AWS Lambda solved the security and independent scaling issues, at the cost of latency.
What comes next?
V2 - Server Groups
Quoting myself from the previous post - we liked everything about running transformations as a separate, independently scalable component. We just didn't like that component running as a Lambda function. So, the natural evolution was to move off of Lambda and run the transformation process as a standalone service.
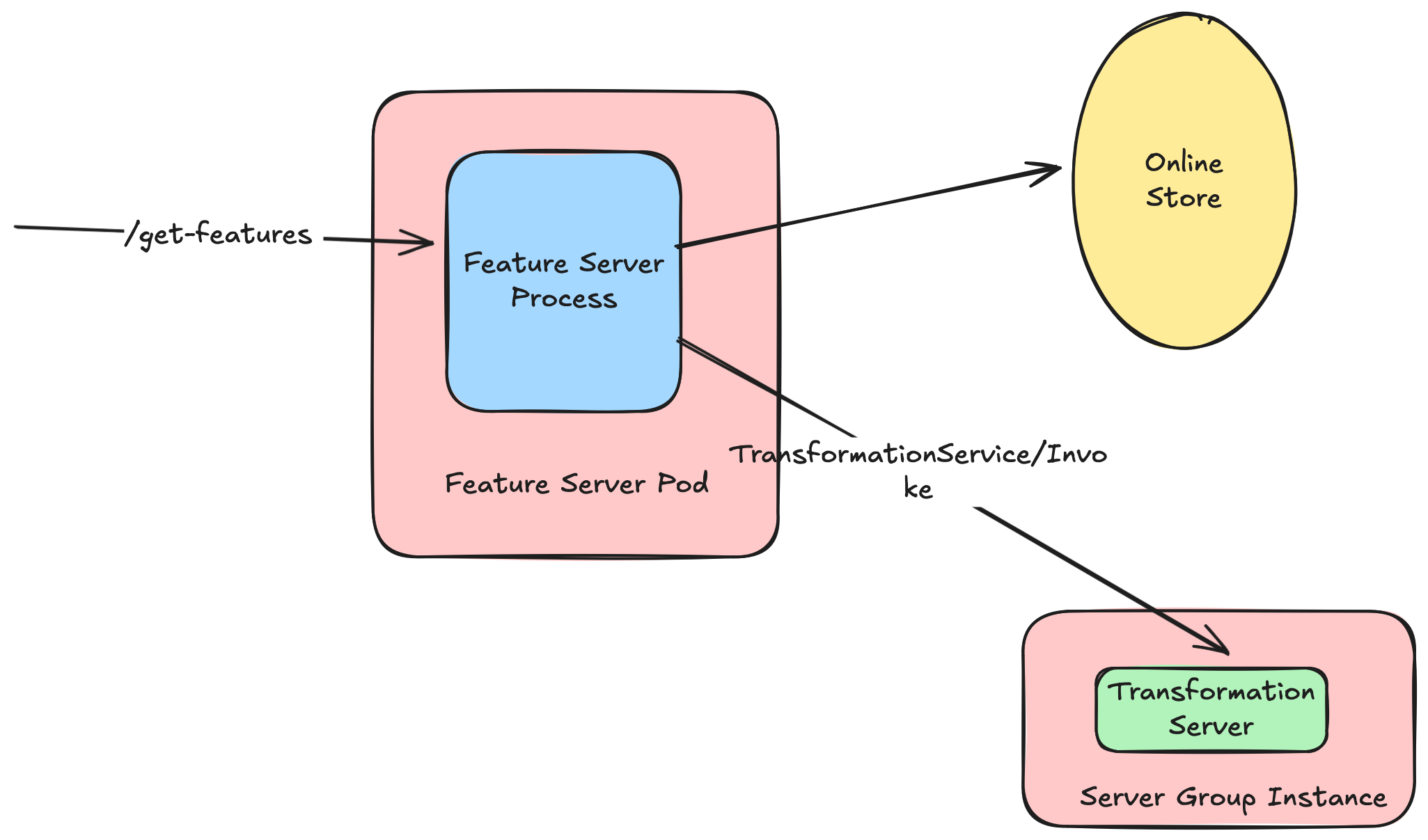
To enable this, the concept of environments were crucial - but not sufficient. Environments represented the encapsulated set of dependencies needed at runtime - but an environment also represented a unit of compute, that was independently callable.
In V2, we wanted to de-tangle these two concepts: "what" is in the execution environment, and "which instance" of the execution environment exists. This allows environments to be created once, but used multiple times.
This brings us to the concept of Server Groups. We introduced the notion of a Transform Server Group, which were individual instantiations on an environment. Transform Server Groups (TSGs) were backed by AutoScaling Groups, and could be created/managed as other python based objects in users' feature repos.
from tecton import ProvisionedScalingConfig
from tecton import TransformServerGroup
fraud_team_tsg = TransformServerGroup(
name="fraud_team_tsg",
description="Fraud detection team Transform Server Group",
owner="fraud-detection",
environment="my-custom-env", # The name of the environment from step 2
scaling_config=ProvisionedScalingConfig(
desired_nodes=3,
),
)When applied, Tecton's control plane would create the ASG on demand using Pulumi, maintaining metadata about the requested infrastructure, and periodically ensuring that created infrastructure matched what was requested (and no drift was introduced, erroneously or manually).
We also maintained our own AMI where we installed necessary dependencies (e.g. security agents and such) using Packer.
We updated our tecton-runtime package to expose the gRPC service that we used during the V0 implementation over a port, in addition to a Unix Domain Socket. We also validated that environments that were used by a TSG used a compatible version of the tecton-runtime package, with these introduced changes.
For communication between the Feature Server process and the TSGs, we opted for client-side load balancing from feature servers to transformation servers. We could have used something like ALB in the middle, but opted to minimize intermediate infrastructure.
Why ASGs and not Kubernetes?
An interesting thing here is that we chose to deploy Transform Server Groups to AWS Autoscaling Groups, and not Kubernetes, in spite of already having Kubernetes running our control plane. Why?
To answer this, there's some value in diving into Tecton's broader architecture.
Tecton ran essentially two "planes" - the control plane, and the data plane. The control plane ran all the metadata APIs, the UI, our metadata datastore, orchestration etc. Essentially, anything that was metadata, but didn't touch the actual data itself.
The data plane is typically where computed features would be stored - and where any job (e.g. Spark jobs) would be executed. This way, the control plane could create and manage jobs running in the data plane - without having access to the said data.
Now.. feature serving ran in the control plane, but in this model, we wanted to move it to the data plane (using Feature Server Groups). Which meant that Transformation Server Groups would need to live in the control plane as well.
Now, I don't know if y'all have tried to manage and secure a Kubernetes clusters' API server across account/VPC boundaries. We had. We didn't like it. Kubernetes has a massive surface area, and we didn't feel equipped operationally to run a K8s cluster securely in our customers' data planes.
On the flip side.. Managing infrastructure using the AWS APIs was trivial using the appropriate IAM permissions for our control plane roles.
Plus - using ASGs allowed us to minimize latency for scaling operations by using tricks like AMIs pre-baked with the dependencies we needed. It resulted in a performant and frankly simpler architecture.
Ingestion-Time Transformations, Traffic Isolation and QoS
The decoupling of dependencies and specific execution environments meant that we could make as many server groups as we wanted. This meant that we could isolate workloads by assigning them to specific server groups via the Tecton DSL. This bifurcated traffic would protect the overall system from spikes in a single serving workload.

In fact, this was the start of a new way of thinking for realtime infrastructure at Tecton. Previously, we had a single feature serving environment - but if we could let users create and manage multiple Transform Server Groups, why not also multiple Feature Server Groups? Or Ingestion Server Groups? This turned so many performance issues we had run into previously on their head - instead of optimizing a fleet that ran heterogeneous workloads, we made it trivial to separate workloads so that they were homogeneous within a set of Server Groups.
from tecton import FeatureServerGroup
from tecton.framework import configs
fraud_group = FeatureServerGroup(
name="fraud-server-group",
scaling_config=configs.AutoscalingConfig(min_nodes=1, max_nodes=2),
owner="fraud-detection",
description="Fraud detection team Feature Server Group",
)FeatureServerGroup definitions. Ingestion Server Groups are left as an exercise to the reader.
This architecture finally meant that we could reuse the transformation server as a base component, across serving and ingestion.
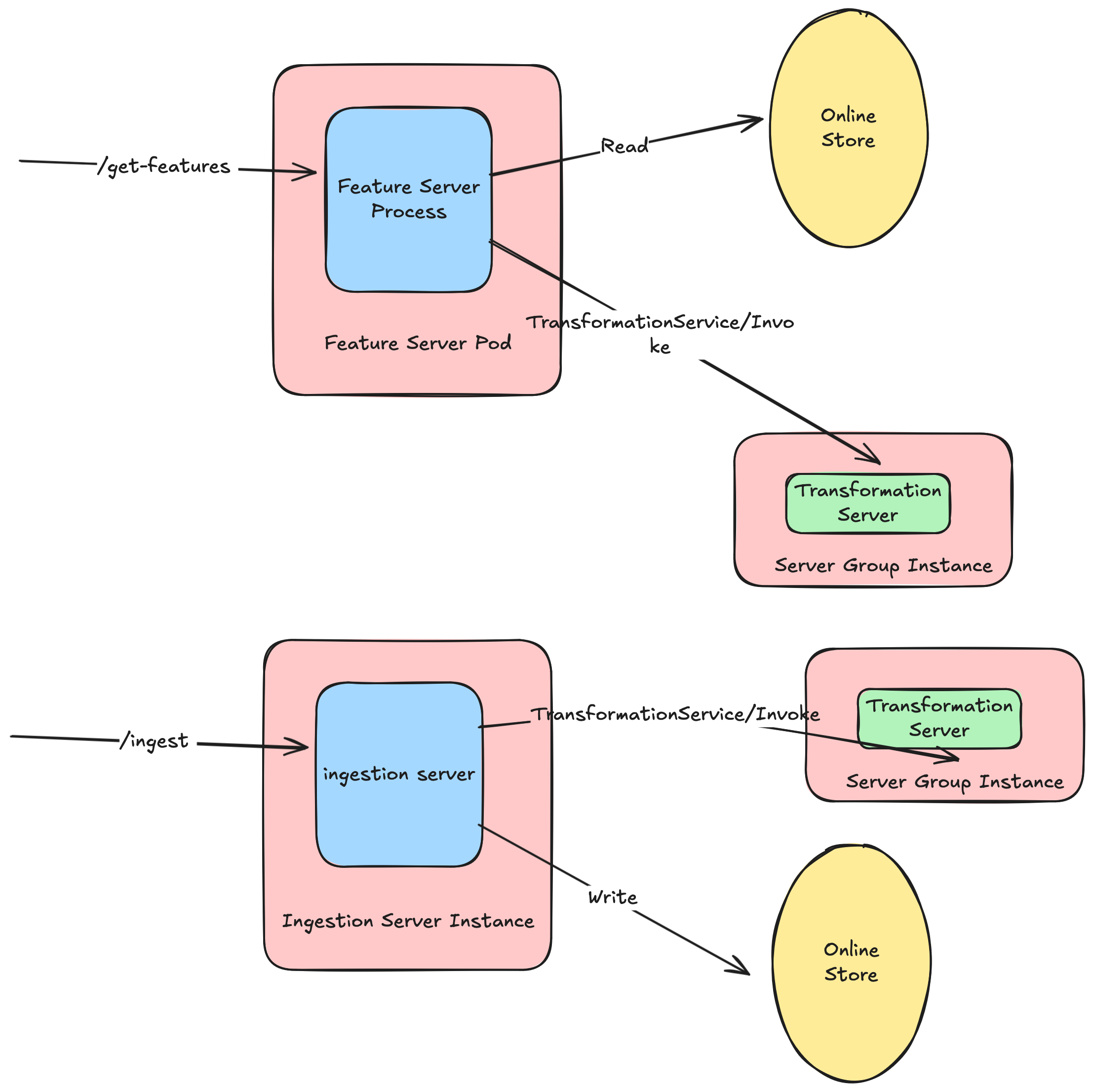
Users could utilize syntax familiar to RTFVs for push-based ingestion.
Performance
This architecture had practically the same performance as our V0 implementation. However, since we decoupled components, the total cost of serving the same traffic came down. And since we could scale independently, we brought down P99 latency for serving realtime feature views from V0 as well. Generally speaking, we were able to use fewer, larger feature server pods - and many, smaller transformation server instances. Intuitively, the python-based transformation processes were bottlenecked by the GIL, and would likely saturate CPU quickly - so they didn't need super large instances.
Alas, I unfortunately don't have specific benchmarks with me.
Why did I love this architecture so much?
I'll admit it - I really really liked this architecture in this context. It made so much sense. We continued to have separately deployed and scalable components. The ASGs backing the TSGs continued to have nerfed IAM roles that we would specify for the ASGs' instance profile. ASG instance counts could be statically configured, or could be set to autoscale based on metrics users could configure (CPU utilization, custom cloudwatch metrics, etc).
It also allowed users to create separate identical transformation environments that could be used to isolate workloads. This meant that spikes in one workload could be served without affecting another workload - critical for a multi-tenant system.
Taking a step back, I was proud how we evolved from a really scrappy V0 to something that made so much sense from first principles. The promise of performance, workload isolation, security and scalability with Server Groups made the infrastructure nerd in me very very happy.
Alas, I didn't really get to see that future come to be - I left Tecton soon after TSGs launched, just before Ingestion Server Groups and Feature Server Groups were about to launch. And pretty soon afterwards, the Databricks acquisition of Tecton was announced. I heard from the grapevine afterwards that Server Groups never really went GA.