Realtime Compute and AWS Lambda


This is followup to https://blog.achals.com/some-thoughts-on-building-realtime-compute-at-tecton/ - focused on how we built a platform for user code execution at Tecton. If you haven't read it yet - you probably should, cause this post will make more sense if you're caught up. 😄
We left off at a pretty big question - how we let users run code to transform their data before it gets written into online/offline storage?
There's a few dimensions along which we're constrained:
- How do users express their transformations? Broadly, the spectrum is declarative (i.e. SQL) to imperative (i.e. a fully fledged programming language like Python).
- Where do these transformations run? Are they run as a separate service, or colocated with existing services?
This problem describes not just an aspect of the problem that Tecton had to solve, but something very general purpose - while I have never worked at places like Modal, it seems intuitively that the problems - and options - they face are quite similar.
V0 Implementation
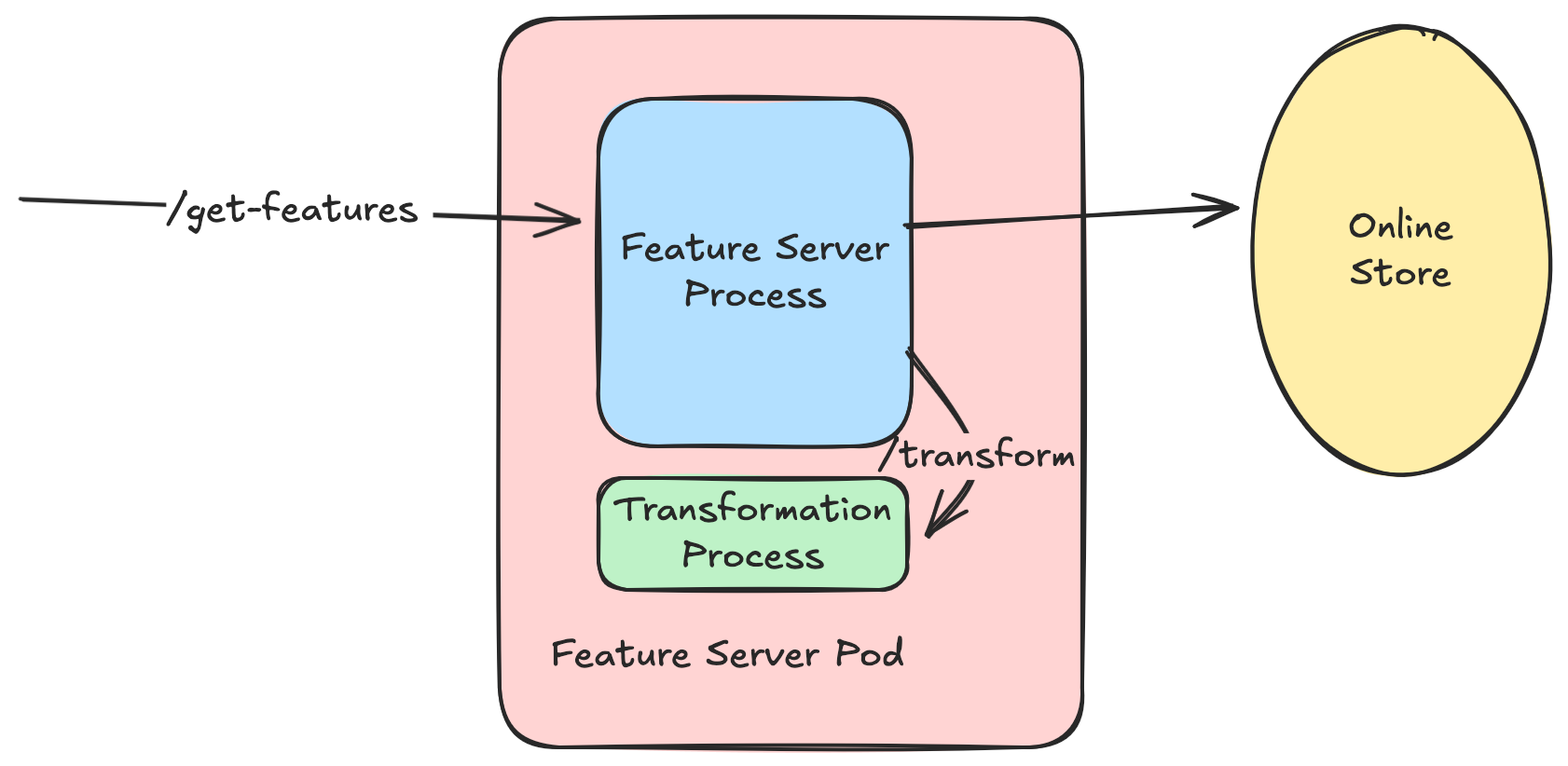
At Tecton, there was a V0 implementation that found its way into production - we allows users to express transformations as Python UDFs. These UDFs would run in a Python sub-process, colocated next to every single Feature Server process. The Feature Server would retrieve records from the online store, pass them into the python interpreter for processing, and retrieve the response and return it callers.
This worked. In a manner of speaking. It wasn't really a reusable component (yet) and had quite a few points of concern.
- Extremely tied to feature serving architecturally - by which I mean it ran as a subprocess managed by the feature server process. So:
- There was no independent service that we could make an RPC call to - it couldn't scale independently.
- In fact, since the feature server and the transformation server ran in the same container - there were challenges with resource contention between the two processes.
- Additionally, the transformation server binary was built and managed by Tecton - this meant that we were in control of what dependencies were available at transformation time - users had no control over this. They couldn't bring in 3p dependencies - or even other 1st party dependencies. In fact, adding any dependency was adding baggage to all the customers who didn't need said dependency - and increasing our support burden.
- Finally, and probably most importantly - if you think about the permission model, you'll notice that the python process is effectively running with the same credentials as the feature server process. But.. the feature server process is a privileged process, but the code the transform server is running can be.. well, arbitrary user code. This is a security nightmare!
So, where does that leave us? Lets look at things from the lens of an ideal system to solve this problem:
- We want to decouple transformations and other callers (feature server, ingestion, etc). We want to scale these separately.
- Going further down this path, we want to have a different set of credentials for the transform server. This allows us to effectively isolate user code from the rest of production environment and nerf and security constraints.
- Secondary - we want the environment to be buildable by users. This will allow users to dictate the environment and dependencies - and have full control of the execution environment.
- This has an interesting corollary - if users need to build the environment with their dependencies, they need to include the an entrypoint/runtime component that will allow our services to talk to the transformation server. Which implies that the transformation server needs to be a standalone library that users can include in their python environments and Docker images.
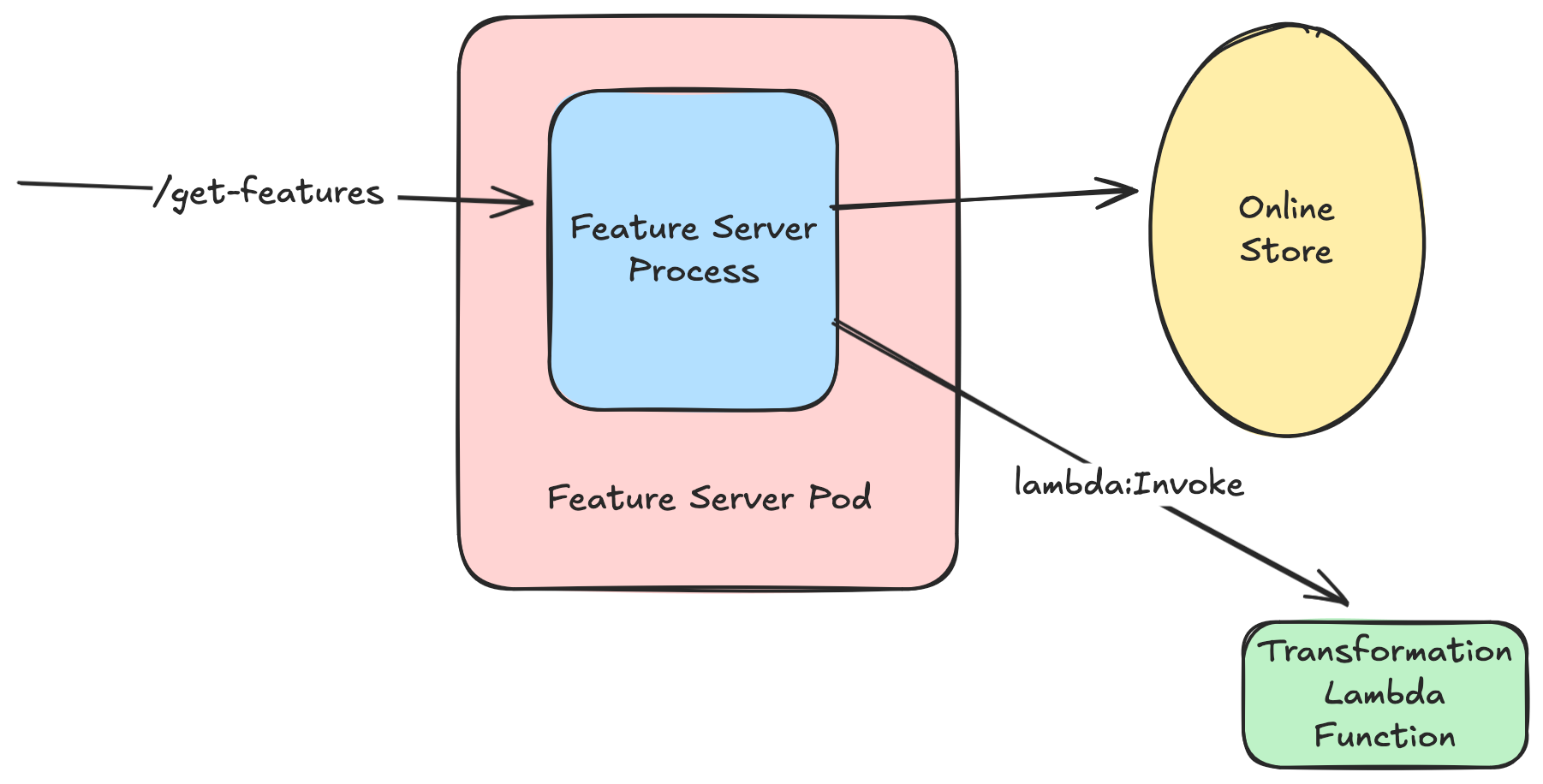
V1 - Transformations in AWS Lambda
To satisfy these requirements, we re-architected the our feature serving system to decouple the transformation server from the feature server. The natural question being - where do transformations get executed now?
For this pass, we did some benchmarking on some architectures - running as a separate standalone service in our existing Kubernetes cluster, vs running the transformations on AWS Lambda.
Our speed of iteration on AWS Lambda was actually pretty fantastic. We were able to get up and running rather quickly. Early rudimentary benchmarks promised easy scaling, but a minimal latency hit (~20ms P99 latency degradation). In our view, this latency disruption was an acceptable tradeoff given the potential cost savings (since we'd only pay for usage on transformations, and would need fewer cores for feature serving). We would also have a different, nerfed IAM role while executing the transformation Lambda. It's a natural use for this kind of use case.
So, we introduced the concept of environments. Quoting the docs:
Tecton allows users to create custom Python Environments for Realtime Feature Views. These environments can be created using a python requirements file that includes all the dependencies required in the custom environment.
Users could create environments via the following command:
tecton environment create --name "my-custom-env" --description "This is a custom environment" --requirements /path/to/requirements.txtWhere the requirements would be something like:
# PyPI packages
fuzzywuzzy==0.18.0
tecton-runtime==1.0.1
# Packages from GitHub repositories
git+https://@github.com/<owner>/<repository>.git@<commit-ish>#egg=<package-name>
# Local wheel files
./wheels/my_local_package.whl
../other_project/wheels/another_local_package.whl
# Wheel files from S3
https://s3.amazonaws.com/my-bucket/wheels/s3_package_1.whl
https://s3.amazonaws.com/my-bucket/wheels/s3_package_2.whlOur CLI would slurp up all these packages, upload them to Tecton, which would bake them into a docker image, and prepare a Lambda function that fronted the Image.
Lambda functions require attached execution roles. Under the hood, we created a new role for the function, with no permissions other than the assumeRole policy required by Lambda. This ensured that the user code couldn't modify our infrastructure, by working on the principle of least-privilege. We also ran the Lambda in a separate VPC which did not have an internet gateway/NAT gateway. This way we could also ensure no outbound connections to the general internet.
Then, users could specify the names of this environment constraints in the definition of a Realtime Feature View.
from tecton import realtime_feature_view, RequestSource, Attribute
from tecton.types import Field, Int64, String
request_schema = [Field("text", String)]
similarity_request = RequestSource(schema=request_schema)
@realtime_feature_view(
sources=[similarity_request],
mode="python",
features=[Attribute("similarity", Int64), Attribute("partial_similarity", Int64)],
environments=["my-custom-env"],
)
def fuzzy_similarity(request):
from fuzzywuzzy import fuzz
baseline = "Mocha Cheesecake Fudge Brownie Bars"
result = {
"similarity": fuzz.ratio(baseline, request["text"]),
"partial_similarity": fuzz.partial_ratio(baseline, request["text"]),
}
return resultUsers could then set the execution environment for a Feature Service containing the above RTFV, and under the hood we would route the transformation request to be executed on the Lambda function instead of the transformation server subprocess:
from tecton import FeatureService
from ads.features.realtime_feature_views.similarity import fuzzy_similarity
similarity_feature_service = FeatureService(
name="similarity_feature_service",
realtime_environment="my-custom-env",
online_serving_enabled=True,
features=[fuzzy_similarity],
)So, how'd it perform?
Terribly. 🫠
The problem we encountered in production was the latency impact was much, much worse than demonstrated in our benchmarks. Specifically with spiky traffic, cold start problems would manifest starkly, dragging our P99 latencies down by 700-1000ms. In some cases, even worse!
The other interesting thing we noticed was that latency would actually grow quadratically with the size of the Lambda payload. This increase in latency couldn't be tracked to our code - it was before the lambda instance even started executing our code. Our best guess is that there's some kind of request copying/buffering that's happening somewhere in Lambda machinery before our the function is ready to execute, which is introducing this latency.
This basically would not even support some use cases that were already in production. A complete no-go from a product perspective. We underestimated how much of a penalty bursty traffic would incur when using Lambda, and how often we would run into cold start issues. Our benchmarks were not entirely representative of the traffic patterns we saw in production.
We knew we were on to something with the idea of decoupling the transformations, but we just hadn't managed to get the architecture quite right.
The things we did like:
- Independent scaling
- Low privilege code execution
- Custom dependencies
The things we did not like:
- The black-box nature of serverless providers.
Basically, the challenge didn't exist in our code - which was pretty lean. The performance challenges existed before our code even started executing, and there was no control we had over that - that was all Lambda and how it functioned.
Lesson learned: latency sensitive use cases with spiky traffic are not a good fit for serverless approaches. The main challenge we faced is not necessarily that the latency was high - it was - but that it was unpredictable. We could not offer a strong SLO. And since the variance was due to factors out of control - back to the drawing board we went. I'll describe our next (and successful) solution next post.